Intro
In this post, we present a novel framework called multiple-input multiple-output self-attentive gated recurrent neural network (MIMO SAGRNN) for binaural speaker separation, which produces a binaural estimate for each of the target speakers with preserved interaural cues. This approach was proposed in our paper titled "SAGRNN: Self-Attentive Gated RNNs for Binaural Speaker Separation with Interaural Cue Preservation", accepted by IEEE Signal Processing Letters.
In this study, the goal of binaural speaker separation is to separate \(C\) concurrent binaural speech signals \(\mathbf{s}_1, \dots, \mathbf{s}_C\) from a sound mixture \(\mathbf{y}\), where \(\mathbf{y} = \sum_{c=1}^C \mathbf{s}_c\) (noise-free condition) or \(\mathbf{y} = \sum_{c=1}^C \mathbf{s}_c + \sum_{c_n=1}^{C_n} \mathbf{n}_{c_n} \) (noisy condition). Here \(\mathbf{n}_{c_n}\) denotes the \(c_n\)-th binaural noise signal and \(C_n\) the number of noise sources. We assume that there is no room reverberation in the acoustic environment.
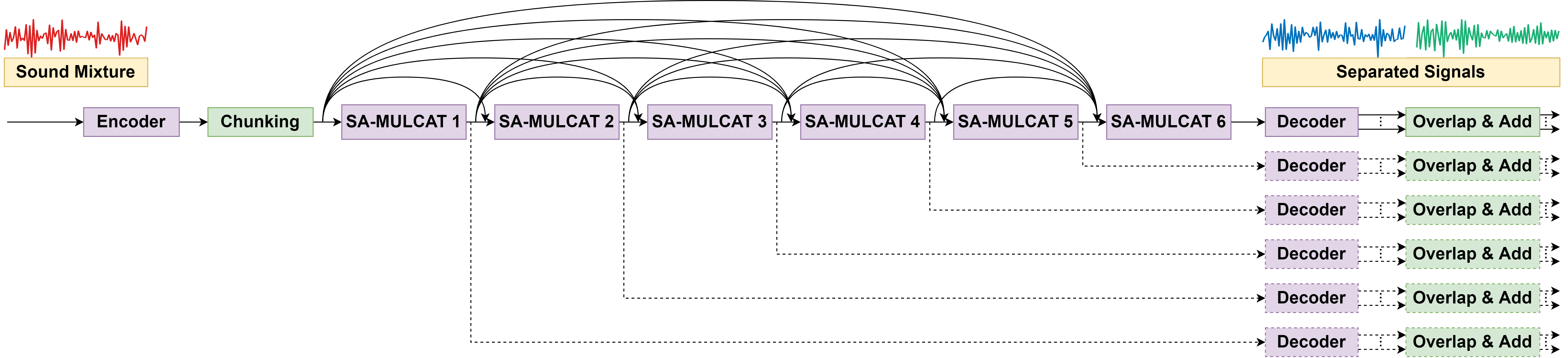
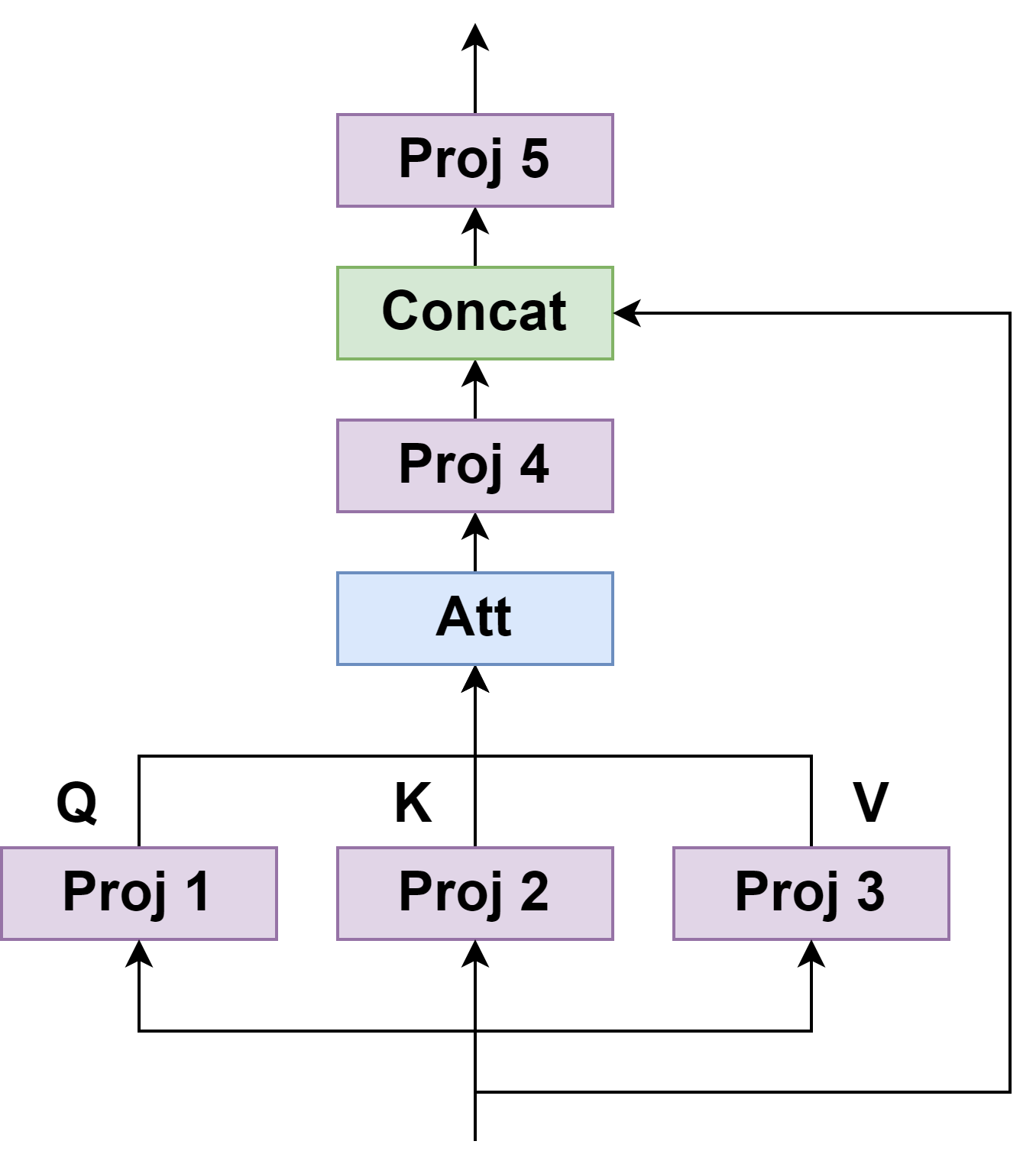
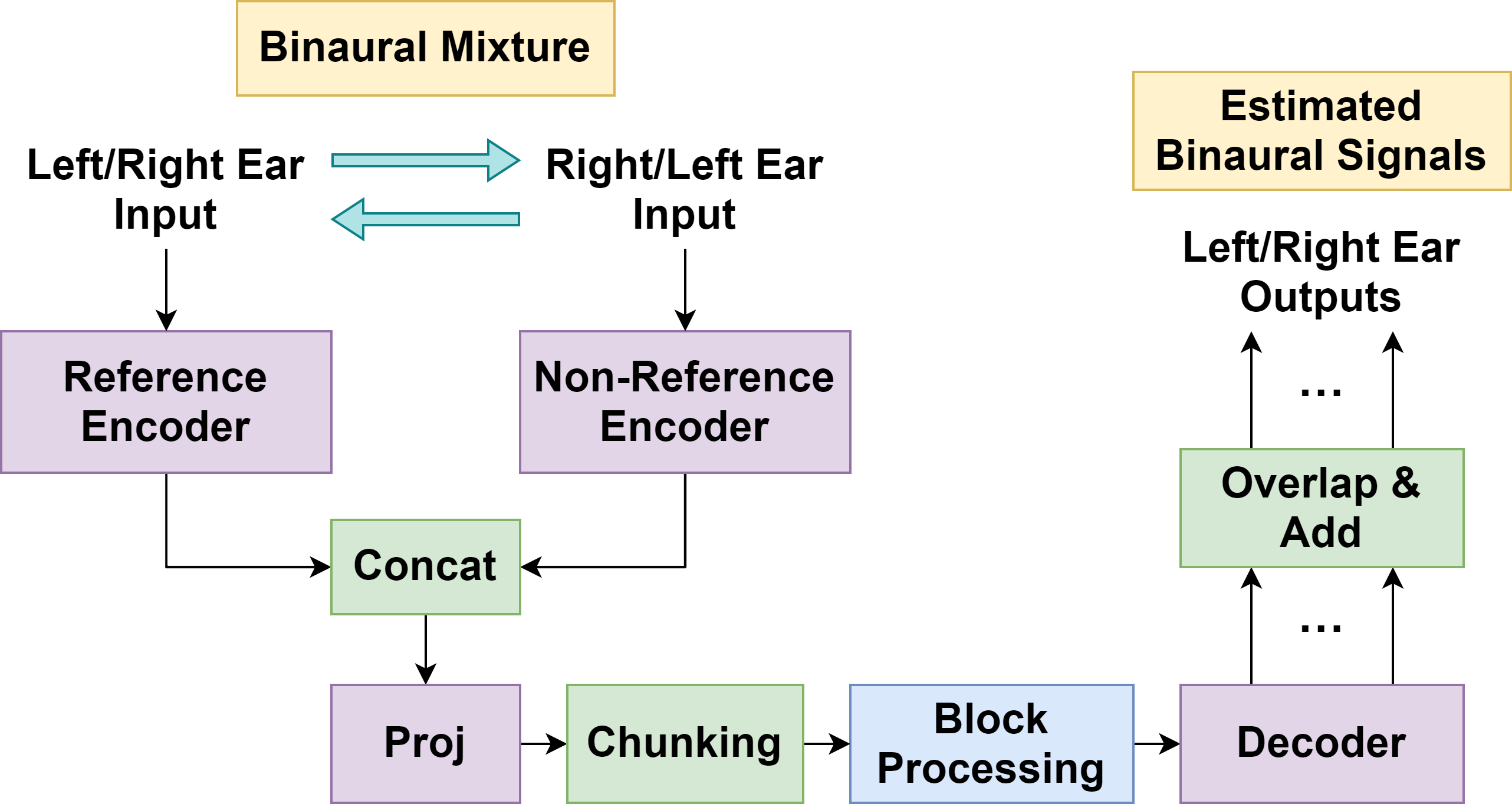
The SAGRNN network architecture extends the gated RNN in [1] by additionally incorporating self-attention mechanisms and dense connectivity. MIMO SAGRNN is then derived from a single-input single-output (SISO) SAGRNN by first extending the SISO SAGRNN into a multiple-input single-output (MISO) layout, in which we create two encoders, one for the reference ear input and the other for the non-reference ear input. This MISO SAGRNN estimates the separated signals in the reference ear. The MIMO system is formulated by alternately treating each ear as the reference ear, yielding estimates for both ears in a symmetric manner.
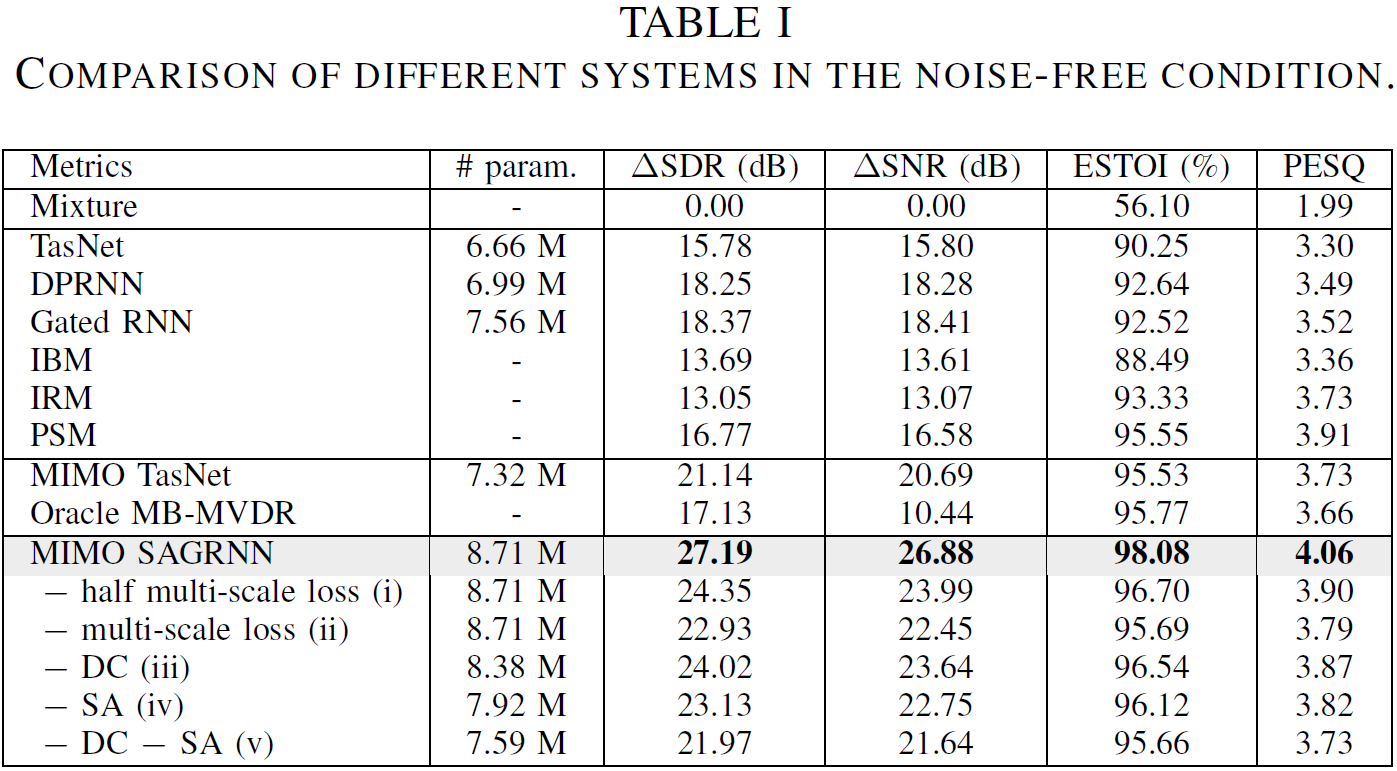
Our experimental results show that the proposed approach significantly outperforms a recent binaural separation approach (i.e. MIMO TasNet [2]) in terms of ΔSDR, ΔSNR, ESTOI and PESQ. Moreover, our approach effectively preserves the auditory spatial cues of talkers.
For full details, see our paper.

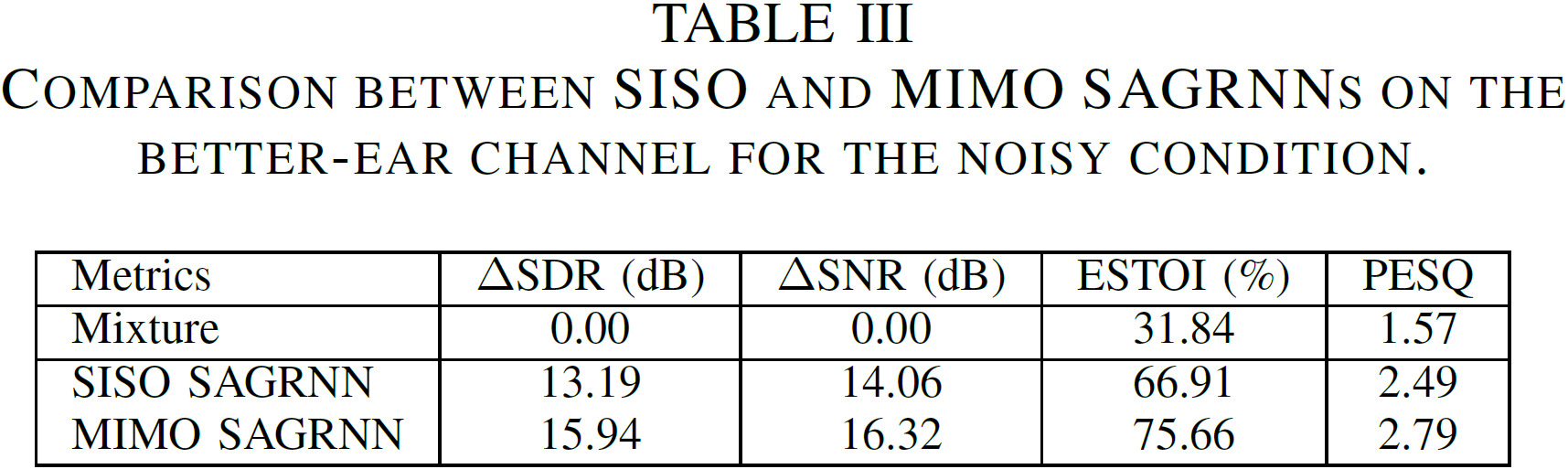
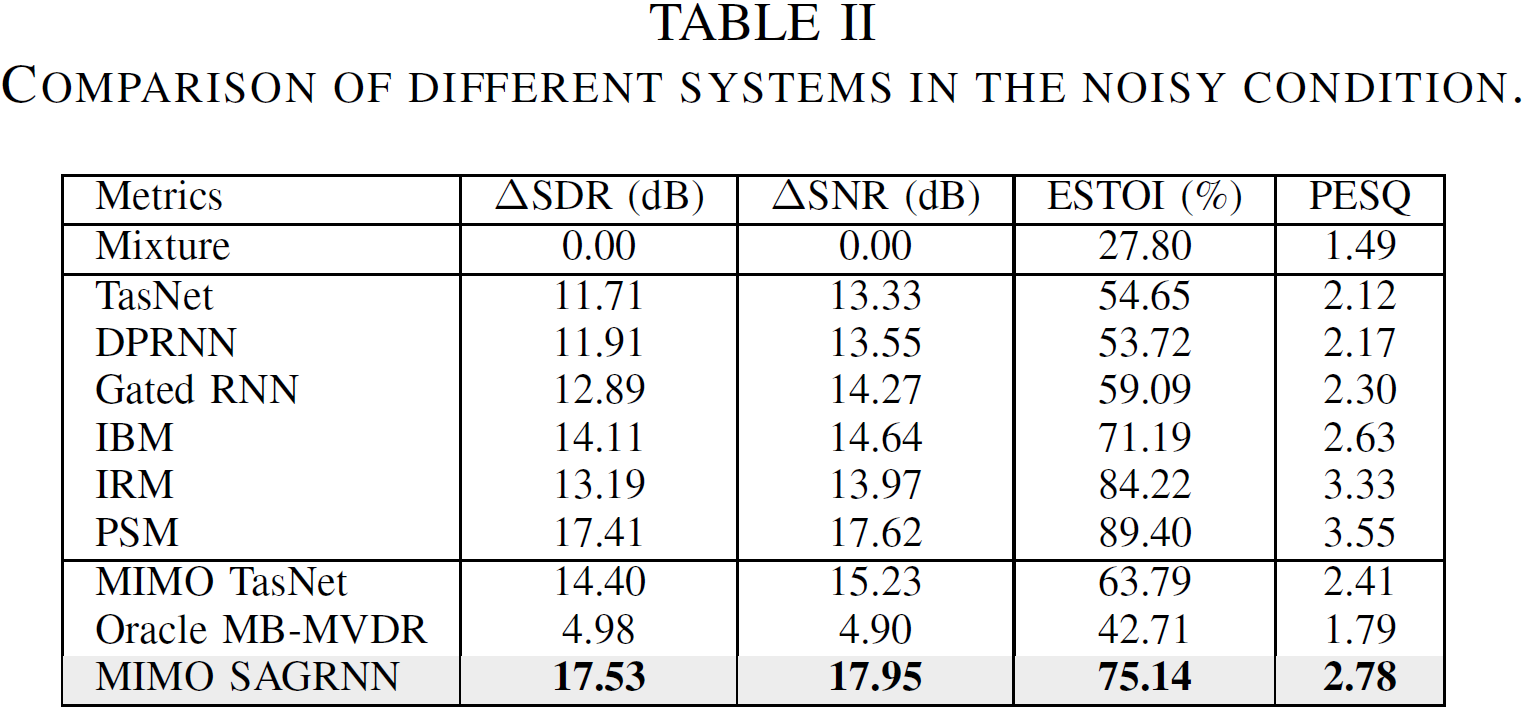
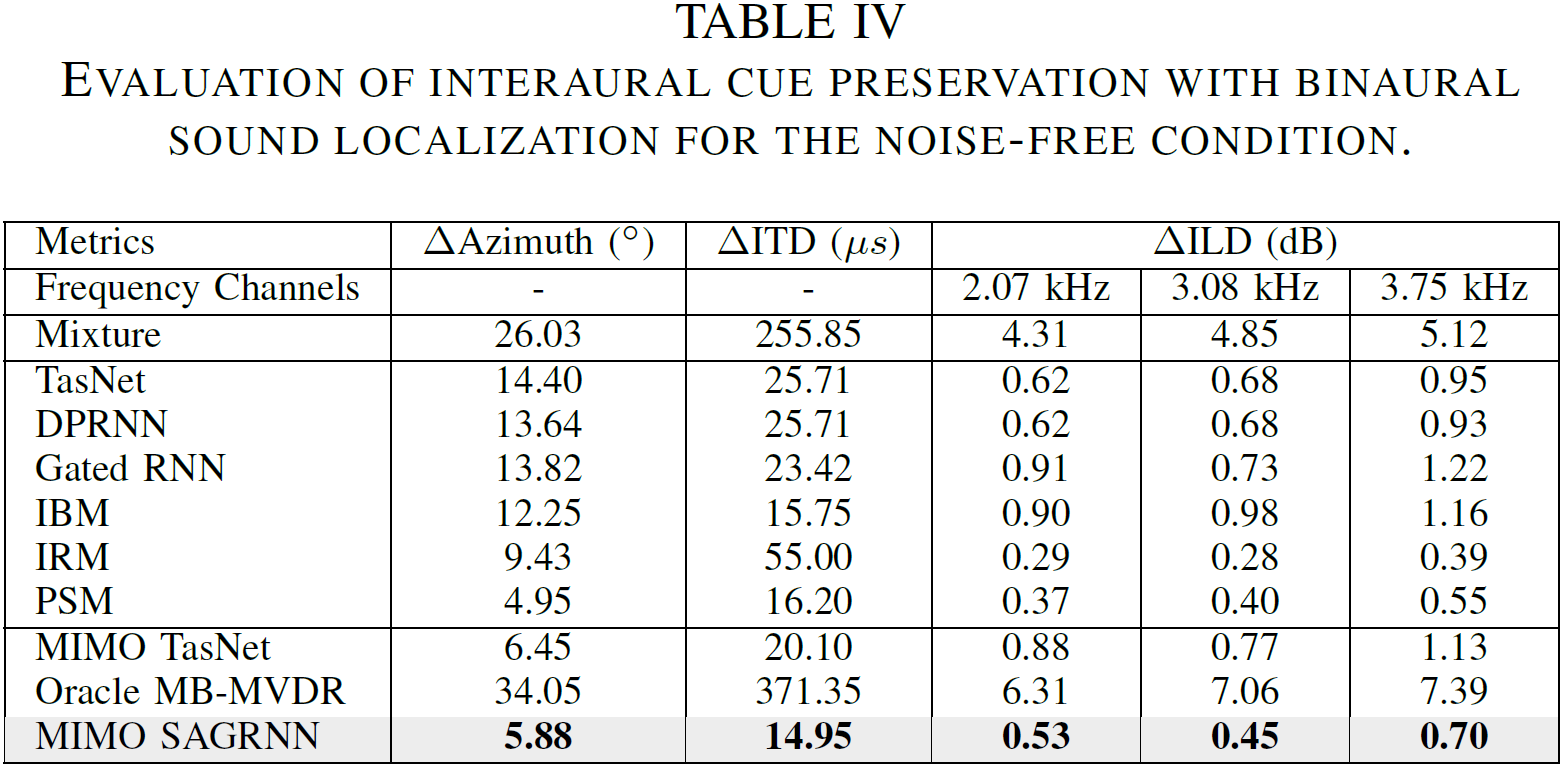
Samples
Here are some (binaural) audio samples for listening:
- Unprocessed Mixture - original binaural sound mixture
- MIMO TasNet - refer to the approach in [2], where the network configurations are slightly changed such that the model is noncausal and has a comparable size to our model
- MIMO SAGRNN - refer to our proposed approach
I. Male-Female Mixtures
| Sample IDs | Unprocessed Mixture | MIMO TasNet | MIMO SAGRNN |
|---|---|---|---|
| A | |||
| B | |||
| C | |||
II. Male-Male Mixtures
| Sample IDs | Unprocessed Mixture | MIMO TasNet | MIMO SAGRNN |
|---|---|---|---|
| D | |||
| E | |||
| F | |||
III. Female-Female Mixtures
| Sample IDs | Unprocessed Mixture | MIMO TasNet | MIMO SAGRNN |
|---|---|---|---|
| G | |||
| H | |||
| I | |||
IV. A "Crossfading" Demo
The following demo crossfades between two binaural speech signals separated by our MIMO SAGRNN. You can first click the "Play/Stop" button to start repeatly playing the audios, and then drag the scroll box to adjust the weighting factors for crossfading (or remixing) the two speakers. You need to wear a headphone for binaural hearing, and we expect you to perceive the different directions of the two speech sources. This demo is created to help demonstrate that the interaural cues are preserved in the separated speech signals by our approach.References
[1] E. Nachmani, Y. Adi, and L. Wolf. Voice separation with an unknown number of multiple speakers. In International Conference on Machine Learning, 2020.
[2] C. Han, Y. Luo, and N. Mesgarani. Real-time binaural speech separation with preserved spatial cues. In IEEE International Conference on Acoustics, Speech and Signal Processing, pages 6404–6408. IEEE, 2020.
Licenses
I. The CIPIC HRTF Database
Website: https://www.ece.ucdavis.edu/cipic/spatial-sound/hrtf-data/
Copyright Notice: THE REGENTS OF THE UNIVERSITY OF CALIFORNIA MAKE NO REPRESENTATION OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND SPECIFICALLY DISCLAIM ANY IMPLIED WARRANTIES OR MERCHANTAB ILITY OR FITNESS FOR ANY PARTICULAR PURPOSE. Further, the Regents of the University of California reserve the right to revise this software and/or documentation and to make changes from time to time in the content hereof without obligation of the Regents of the University of California to notify any person of such revision or change.
Citation: V. R. Algazi, R. O. Duda, D. M. Thompson, and C. Avendano. The cipic hrtf database. In Proceedings of the 2001 IEEE Workshop on the Applications of Signal Processing to Audio and Acoustics (Cat. No. 01TH8575), pages 99–102. IEEE, 2001.
II. WSJ0
Website: https://catalog.ldc.upenn.edu/LDC93S6A
License(s): LDC User Agreement for Non-Members
Citation: J. Garofolo, D. Graff, D. Paul, and D. Pallett. Csr-i (wsj0) complete ldc93s6a. Web Download. Philadelphia: Linguistic Data Consortium, 83, 1993.
III. Freesound Noises
Website: https://freesound.org/people/Robinhood76/
Attribution Noncommercial: http://creativecommons.org/licenses/by-nc/3.0/